Paula Abbott presented a session to Unity Learning Communities to inform our program development. Those attending also felt that this information is critical to how we design our program AND imperative to supporting our community. As a presentation is difficult to replicate in other formats by simply sharing a presentation, we'd like to get this information out to the public in other ways.
All Unity Learning Community Learning providers will have training in ACE, become aware of their own ACE scores and solutions, and learn instructional approaches to support learners.
Unity Learning Community Learning will post a series of information on social media to build awareness. Additional community trainings will also be provided.
Here is the draft of postings.
Introductory Post: ACE stands for Adverse Childhood Experiences. Bad things happen to all of us...it's normal. But when children experience these things between 0-17, they may have long term problems with health, opportunities, and well-being. Even worse, some groups experiences these kinds of traumas more than other groups. It's important to know how we can stop these experiences from ever happening and to help folks heal once they have occurred.
In a series of social media posts and other activities, Unity Learning Communities will focus on sharing important ideas an solutions with our communities.
Learn more about ACES here: https://www.cdc.gov/aces/about/index.html
Trauma comes from 3 major sources: The Household, The Community, and The Environment. We aren't "doomed" because we have experienced bad things. But it is important to be aware of where the difficulties arise so we prevent some of them and so we can seek ways to recover.
6. Adverse Childhood Experiences: There’s an unmistakable link between
ACEs and adult onset of chronic
disease, mental illness, violence and
being a victim of violence. https://www.pacesconnection.com/pages/3RealmsACEs.
7. Adverse Childhood Experiences: The more types of childhood adversity,
the direr the consequences. An ACE
score of 4 increases the risk of alcoholism by 700%, attempted suicide by
1200%; it doubles heart disease and
lung cancer rates. https://www.pacesconnection.com/pages/3RealmsACEs.
9. Adverse Childhood Experiences: One type of ACE is no more damaging
than another. An ACE score of 4 that
includes divorce, physical abuse, a
family member depressed or in prison
has the same statistical outcome as
four other types of ACEs. This is why
focusing on preventing just one type
of trauma and/or coping mechanism
isn’t working. https://www.pacesconnection.com/pages/3RealmsACEs.
11. Our brains are plastic. Our bodies want to heal. To reduce stress hormones in
our bodies and brains, we can meditate, exercise, sleep and eat well, have safe
relationships, live and work in safety, ask for help when we need it. https://www.pacesconnection.com/pages/3RealmsACEs.
13. ACEs are common. About 64% of adults in the United States reported they had experienced at least one type of ACE before age 18. Nearly one in six (17.3%) adults reported they had experienced four or more types of ACEs.7https://www.cdc.gov/aces/about/index.html
14. Three in four high school students reported experiencing one or more ACEs, and one in five experienced four or more ACEs. ACEs that were most common among high school students were emotional abuse, physical abuse, and living in a household affected by poor mental health or substance abuse.8https://www.cdc.gov/aces/about/index.html
15. Preventing ACEs could potentially reduce many health conditions. Estimates show up to 1.9 million heart disease cases and 21 million depression cases potentially could have been avoided by preventing ACEs.1 Preventing ACEs could reduce suicide attempts among high school students by as much as 89%, prescription pain medication misuse by as much as 84%, and persistent feelings of sadness or hopelessness by as much as 66%.8https://www.cdc.gov/aces/about/index.html
16. Some people are at greater risk of experiencing one or more ACEs than others. While all children are at risk of ACEs, numerous studies show inequities in such experiences. These inequalities are linked to the historical, social, and economic environments in which some families live. 56ACEs were highest among females, non-Hispanic American Indian or Alaska Native adults, and adults who are unemployed or unable to work.7https://www.cdc.gov/aces/about/index.html
17. ACEs are costly. ACEs-related health consequences cost an estimated economic burden of $748 billion annually in Bermuda, Canada, and the United States.9https://www.cdc.gov/aces/about/index.html
18. ACEs can have lasting effects on health and well-being in childhood and life opportunities well into adulthood.10 Life opportunities include things like education and job potential. These experiences can increase the risks of injury, sexually transmitted infections, and involvement in sex trafficking. They can also increase risks for maternal and child health problems including teen pregnancy, pregnancy complications, and fetal death. Also included are a range of chronic diseases and leading causes of death, such as cancer, diabetes, heart disease, and suicide.11112131415161718https://www.cdc.gov/aces/about/index.html
19. ACEs and associated social determinants of health, such as living in under-resourced or racially segregated neighborhoods, can cause toxic stress. Toxic stress, or extended or prolonged stress, from ACEs can negatively affect children’s brain development, immune system, and stress-response systems. These changes can affect children’s attention, decision-making, and learning.19https://www.cdc.gov/aces/about/index.html
20. Children growing up with toxic stress may have difficulty forming healthy and stable relationships. They may also have unstable work histories as adults and struggle with finances, job stability, and depression throughout life. 19These effects can also be passed on to their own children.202122 Some children may face further exposure to toxic stress from historical and ongoing traumas. These historical and ongoing traumas include experiences of racial discrimination or the impacts of poverty resulting from limited educational and economic opportunities.16https://youtu.be/8gm-lNpzU4ghttps://www.cdc.gov/aces/about/index.html
22. Nurture and protect kids as much as possible. Be a source of safety and support. https://www.pacesconnection.com/ws/Handouts_ParentingPreventACEs_EN.pdf
23. Move and play with your kids. Drum, stretch, throw a ball. Dance. Move inside or outside for fun and togetherness and to ease stress. https://www.pacesconnection.com/ws/Handouts_ParentingPreventACEs_EN.pdf
24. Make eye contact. Look at kids (babies too). It says, "I see you. I value you. You matter. You are not alone." https://www.pacesconnection.com/ws/Handouts_ParentingPreventACEs_EN.pdf
25. Say, "sorry." We all lose our patience and make mistakes. Acknowledge it, apologize, and repair the relationships. It's up to us to show kids we are responsible for our moods and our mistakes. https://www.pacesconnection.com/ws/Handouts_ParentingPreventACEs_EN.pdf
26. Give 20 second hugs. There's a reason we hug when things are hard. Safe touch is healing. Longer hugs are most helpful. https://www.pacesconnection.com/ws/Handouts_ParentingPreventACEs_EN.pdf
27. Slow down or stop. Rest. Take breaks. Take a walk or a few moments to reset or relax. https://www.pacesconnection.com/ws/Handouts_ParentingPreventACEs_EN.pdf
28. Hunt for the good. When there has been pain or trauma, we look for danger. We can practice looking for joy and good stuff too. https://www.pacesconnection.com/ws/Handouts_ParentingPreventACEs_EN.pdf
37: Trauma can impair cognitive development. It literally hurts the brain.
Source: Paula Abbott
38: When children grow up in an environment where they are exposed on a regular basis to what they perceive as a threat, their nervous system is permanently in a state of fight-flight-or-freeze. They are more likely to struggle with emotional distress and regulation, impulsivity, learning difficulties, as well as physical, mental, and health problems.
Hand Model of the brain. https://www.facebook.com/watch/?v=912761219957023
39: Healing from trauma is possible: https://www.youtube.com/watch?v=fa1lsafvxUQ
40: Trauma isn't about what's wrong with you. It's about what happened to you.
A place I like to go is anywhere I've been doing a project. After the tools are put away and the paint has dried, I like to walk out there and just stand. To look at the progress. To bask in the...mess...and what might be next...but mostly to feel the change in what wasn't and now is. To feel how the sound of the place changes the echoes of my footsteps. To see how the sky changes the light with a new structure or the absence of a branch or 5,000. (edited to add of too (excess) many dead branches.
Acting on Impulse Structure.
Thirteen minutes ago, I thought of the outdoor kitchen and all my projects. It's now almost time for lunch, but my mind still sees Jason's hands reaching down form the tar-papered roof to grab the corrugated red panels of metal. He peeks across the panels and down at me with a cautious smile. He's checking to see if the rise hurt my shoulder and if I'm ready to release my grip as he pulls it above my head.
I wanted to talk about all the projects and explain how I feel satisfaction in getting things done. But now I realize that's not really what makes the spaces somewhere I like to go.
Instead, I realize that it's not about what or where but about who was with me during and after the creating.
A Staggering Thing I Saw Structure
I was teaching grammar in Little Elm ISD when mom sent a text message.
It was a picture of Willow and her new kitten foster, Gingerly. Willow's nose was right next to the kitten's.
My heart said, Ahhh! and I felt love for mom and how all creatures flock to her *edited to add like barefooted kids to the cool relief of the snow cone stand). I admired her all over again.
Then it was time for the group to discuss the text structure and conjunctions. The point of which is to know and understand how ideas are connected. How a reader folows the path of reasoning over rocks in a river crossing...arriving with dry feet (edited to add, refining teh clarity of mind, and reviving a purpose behind grammar).
Lynn and I met to discuss the learning process and how we would explain the ideas to those we will serve.
I shared the concept used at Stonefield Elementary to share their vision with the students and the community. https://www.stonefields.school.nz/our-vision-and-values/
We watched this video and examined their images.
I shared and recreated the model of the learning process here: https://www.stonefields.school.nz/learning-at-stonefields-school/ for our notes.
Then we brainstormed how to make the metaphors work for our area.
wind industry - the concept works, but is probably better for adults than it is for students.
canyon - we'd have to go there
prairie
N. Heights - we'd need more research
Garden
Music/Performance
Technology/Cell Phones/Coding
Medical? Can't read my handwriting, sorry
As we thought about our values, what kids find meaningful, we landed on the idea of friends. And that fits really well with Tremaine's vision about community. And friends/relationships are things that kids know a lot about - we won't need to teach another level of content for them to get the metaphor.
We then started to think about how the metaphor fits the learning process.
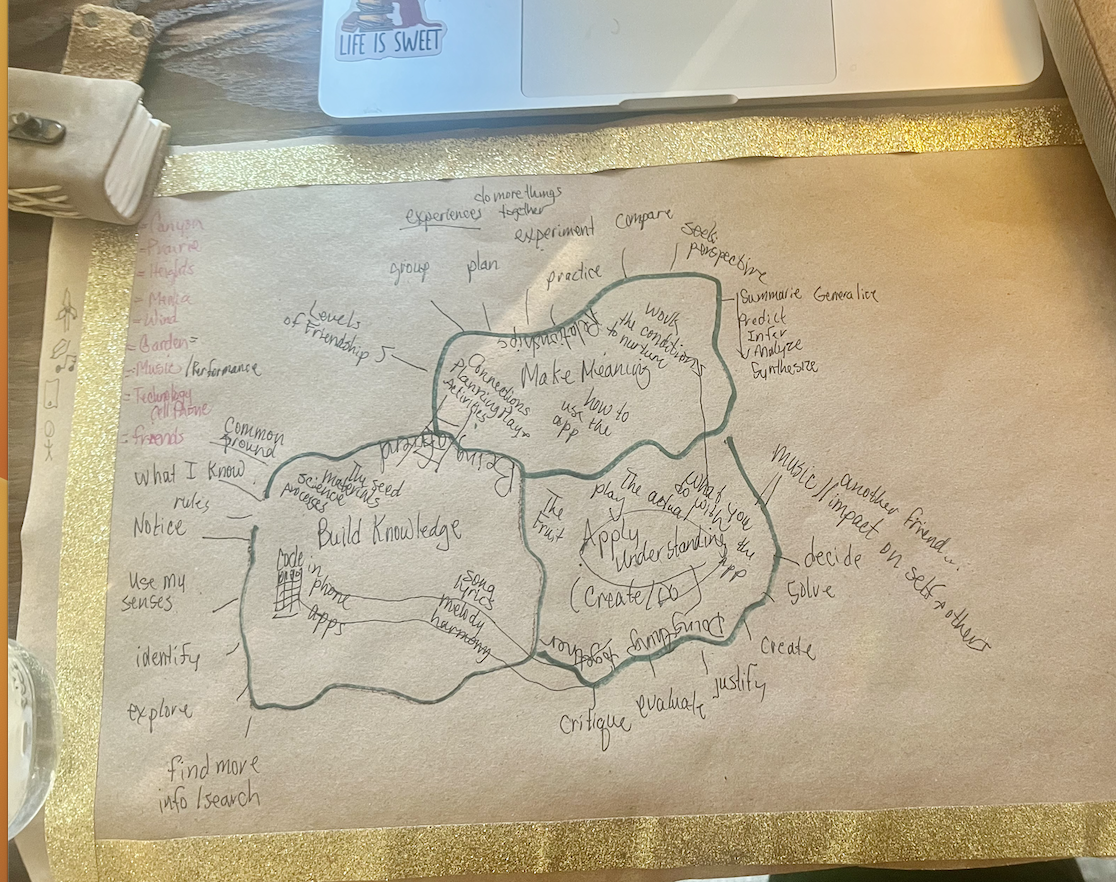
Here's the learning process and the verbs that Stonefields Elementary uses. They conceptualize the learning process as moving and climbing on a set of rocks. We move in an around the area, depending on where we are in the process. For example, we might be making meaning, but realize we have more questions and need to seek more knowledge.
Building Knowledge: We add to our knowing and understanding. We use specific strategies and techniques in this phase which include: bring what I know, notice, use my senses, identify, explore, find more information, search and research
Making Meaning: This is where the knowledge and understanding become more than facts. To achieve this kind of thinking, we group, plan, experiment, practice, compare, seek perspectives, summarize, generalize, predict, analyze, and synthesize.
Applying Understanding: At this phase of learning, we are ready to create, act, or do. We make decisions, solve, critique, evaluate, justify, and create with meaning and purpose.
Using Friendship as the Metaphor
Building Knowledge - We begin by learning how to be a friend and connect to others. This requires us to learn about ourselves and others.
Making Meaning - This is where we build relationships and nurture each other through experiences.
Apply Understanding - This is where we connect beyond friendships to build true community that changes the world. It's how we impact the world together.
Lynn and I are going to share these ideas with the team when we meet next time to get feedback and make decisions on how we'd like to roll out these lessons.
As Lynn and I talked, we created a clarifying outline of the major challenges we want students to know and understand.
Our goal: Make stuff better for kids
Challenge One: Henry's Freedom Box Lesson: What does it mean to be literate? To experience reading and writing powerfully?
Challenge Two: The Learning Pit: What does success involve?
Challenge Three: The Learning Process: How does one learn?
Challenge Four: Learner Characteristics: What does a learner need?
Did anyone else cheers the communion cup on Sunday? As a recovering Baptist, this practice feels sacrilegious and somewhat-sinfully automatic. Raising my hands in church AND using a cultural practice centered around alcohol? My mom used to duck when she even drove by a liquor store. A dangerous practice. Shame heats my face every time I accidentally lift the cup and offer to clink with my neighbor.
But what is more worthy of lifting hands in celebration than Christ's big love? The juxtaposition of church and culture swirls around the dysfunctional way we all approach life and religion. What am I to do with that oxymoron?
Anna, my grand-daughter reminded me of the mismatch of living, loving, politics, and religion. We kneeled on the velvet and needlepoint cushions, waiting for the pastor to offer the blood and body of Christ. We placed our empty hands in prayer over the worn wood, waiting for the host, gesturing in prayer until I heard a little gasp beside me and peeked to see Anna's wide eyes. She brushed the blond wisps from her forehead wrinkled in concern, "OH NONA! We forgot the tip!!" She was horrified. And it was too late to grab a dollar or some coins for the offering.
She had no idea why I smiled and laughed at such a travesty and lapse of obligation to those who serve. My prayer of thanksgiving for Christ's sacrifice and apologies for my failures turned to praise and love for the gentle heart of this child.
She probably cringes to hear this frequently recounted tale much like my son who groans when I delightfully tell about the only time he mispronounced a word in his life: "These are the voyages of the starship, Enterprise, it's contishooing mission to seek out new life and new civililations...to boltly go where no man has gone before..." embarrassment and avoidance at the repeated recollections of innocence.
A recitation again. The same story. The Body of Christ. The Blood of Christ. A few words of a story, legion of emotions, horrors of mistakes, disappointments, pain,...but also of joy, wonder, and awe. Anna's misconstrued understanding of communion and offerings represented her childlike inexperience and the culture of the restaurant industry. Food. Service. Tips. She may have understood it better than any of us.
Like the transubstantiation of the elements, some of us only understand the mysteries through things we know about. As a baker, I'm reminded of the chemical reactions of osmosis when water, flour, and time become bread. Reflection shows me that the cup, the culture, and the living aren't really oxymoronic at all.
The living of life in the time we have, next to people we have only a few moments to love and enjoy...it all mixes together and changes life from one kind of thing to another. I don't think the Lord minds that kind of connection - celebration - at his table. Today, I feel ok about letting go of the guilt around lifting the cup.
On Wednesday, November 20, 2024, Paula Abbot led a session called: Understanding Childhood Trauma and Living a Powerful Life. This flyer was shared on Facebook.
11 community members were present.
I'll be documenting the content of the sessions in a separate format. Many of us felt that the information was personally relevant and helpful. I was able to take a lot of notes that will help me weave in the principles to our approach to families and the lessons we craft for students learning to read.
We plan to offer this information again at another time.
This big experiment on teaching disenfranchised readers...this thing with Tremaine Brown and The Vessel...we met last night to discuss and plan the first interaction with students. I want to write and let you know what's happening. To document the process. To seek your involvement and support.
As we work through building our response to learners, there are many components. Gee describes important theoretical foundations that serve as our framework. The book covers 36 principles of learning situated in 3 areas of current research. We are using these three areas of research to ground our decision making. Basically - we are asking ourselves: How do we USE these "central truths about the human mind and human learning" in our instructional design and approach to the learners we will serve? (Gee, p. 9).
Situated Cognition: Learning happens individually, "inside people's heads" (Gee, p. 9). But it also happens while that person experiences a "material, social, and cultural world" (Gee, p. 9). As we design, support, and respond to each other, we will need to think deeply about how that kid is seeing the world and thinking through how they are living and surviving it.
New Literacy Studies: Reading and writing are more than "mental achievements" that kids experience alone or in the way we experienced them (Gee, p. 9). And it's serious stuff. The mental achievements have consequences: "social and cultural practices with economic, historical, and political implications" (Gee, p. 9). Y'all. The people who have joined us believe in what we are doing with literacy as a moral imperative.
Connectionism: Honestly, this theory points out what I think causes the kids we are working with to struggle with reading and writing. It's the way we are teaching them. It's our system's fault. Hate me if you want - but we have to make some serious shifts in what we think it means to teach. Gee explains that people really aren't good with logical reasoning. You think? Sarcasm overt right there in case you didn't hear it in the font. Gee also explains that we really aren't good with "general abstract principles detached from experience" (Gee, pg. 9). Yet - isn't that exactly what we teach? General abstract principles. We tell kids what the principles are. We wade in abstraction and textual interpretations that begin with logical reasoning and never show how one actually comes to abstraction, principles, generalizations. We give instructions, telling kids what to do, but we never really tell them how to come up with their own ideas or thinking processes. Instead of instruction - actually teaching - we are bossing kids around as if they were some kind of cognitive automaton receiving our programming. Scary stuff. Read James Clavell's The Children's Story if you think that's not what we are doing.
The Learning Pit: A Common Language
To really teach, we must help students look at their experiences in the world, seek their own patterns, and come up with generalizations that govern the experiences as personal truths, cognitive idiosyncracies, and lives. J.E. Dennis described how we cause "epiphany" in our lesson design. I look forward to sharing his thoughts with you soon. James Nottingham describes the concept as "Eureka" in his video on The Learning Pit.
The Learning Pit concept will be a component of how we talk about learning with the readers and writers we serve. You see, a lot of kids think there is something wrong with them because they struggle. S. Carr wrote about an experience with a child she tested for GT and his response. I can't wait to share her writing with you. E. Madrano shared and experience with supporting a new teacher in the classroom management pit. You'll enjoy that one as well.
Turns out, the pit is a universal experience (Thanks Mouserat!)
Each Thought Partner (which is what we call those who directly support learners) will develop their own way of teaching the Learning Pit to their groups. Stay tuned for their approaches. Ultimately, teaching is an individual sport - the way the teacher puts the lesson together changes how students uptake and use the ideas. Thought Partners will share their approach at the next meeting on November 21st.
The First Challenge: Process over Content
After we discussed the theoretical underpinnings, we participated in the first challenge Thought Partners will lead with their groups of three learners. Throughout the experience, the Thought Partners were to consider four purposes and five principles to evaluate and refine the lesson.
It has been said by many that ELAR has no content. After learning phonics, a bit of grammar, and continued vocabulary studies...there's really only process. Video games are like that too - no content. Seems like a waste of time? Not really. Gee points out these important ideas on pages 37 and 38. I added the stuff in the parenthesis relative to our cause.
The Four Purposes
1. Learning to experience (see and act on) the world in a new way. (This is not to get a job or pass STAAR.)
2. Gaining the potential to join and collaborate with a new affinity group. (You belong where you didn't think you could. We are all here to help you do more.)
3. Developing resources for future learning and problem solving in the semiotic domains to which the game is related. (Learn how to play the literacy "game" with skills and processes that make sense to you now and later.)
4. Learning how to think about semiotic domains as design spaces that engage and manipulate people in certain ways and, in turn, help create certain relationships in society among people and groups of people , some of which have implications for social justice. (Learn about what is being done to you and for you and with you that makes yours and other lives better.)
The First Five Principles
Gee explains at the end of the chapter on Semiotic Domains that causing reflection is key to learning (p. 41-42). As such, these first five principles guide how we develop lessons that change the learner experience and impact. I added the stuff in ending parenthesis.
1. Active, Critical Learning Principle: All aspects of the learning environment (including ways in which the semiotic domain is designed and presented) are set up to encourage active and critical, not passive learning. (All lessons must include listening, speaking, reading, writing, thinking, collaboration, arts, movement, trauma informed components.)
2. Design Principle: Learning about and coming to appreciate design and design principles is core to the learning experience. (I don't get this one yet. We are still thinking about what this means with the experiences we are designing for the learners.)
3. Semiotic Principle: Learning about and continuing to appreciate interrelations within and across multiple sign systems (images, words, actions, symbols, artifacts, etc.) as a complex system is core to the learning experience. (Connectionism/constructivism will be key components along with ZPD.)
4. Semiotic Domains Principle: Learning involves mastering, at some level, semiotic domains, and being able to participate, at some level, in the affinity groups connected to them. (We will be building a community and identity different than the one we all hold at school and in the community. And we will be learning about how literate folks navigate and participate in the world.)
5. Metalevel Thinking About Semiotic Domains Principle: Learning involves active and critical thinking about the relationships of the semiotic domain being learned to other semiotic domains. (Nothing we are ever doing will be about a single text or content. We will be learning about systems that relate to all other systems and living a powerful life.) T. Simms discussed connections she saw through her background in Math and Science. I look forward to sharing her ideas as well.
Experiencing and Refining the Challenge
Together, we experienced the first challenge with a powerful text, audio performances, role-play, annotation, graffiti, symbols and anchor backgrounds. Throughout the experience, we modified, debriefed, and discussed experience, processes, design, revisions, etc.
We plan to employ the revisions and lessons with a target group of learners, filming the event, and refining the lesson more fully for final implementation when the project goes live next semester. It is our hope that through collaboration, we embody the same principles of design we seek to create in the relationships and experiences with the learners. These videos will provide training for participants not able to be present.
Documenting the Process
I'm keeping a researcher's notebook during the events. Afterward, I am using the notes to write up what happened and document changes. Using member checks, participants will have access to the summaries and opportunities to revise/comment on the process. Since the blog is public facing, community comment and input is also possible at each phase.
References:
Parlow, A. (2024). Video Games Could Save the World. Unpublished works.
Clavell. J. (1981). The Children's Story. Delacourte Press. Accessed from: https://www3.uwsp.edu/cnr-ap/UWEXLakes/Documents/programs/lakeleaders/crew7/greenlake_may_2008/the_childrens_story_becken_presentation.pdf
Gee, J. P. (2007). What Video Games Have to Teach Us about Learning and Literacy. St. Martin's Griffin.
Mouserat. (2021, June 2). Mouserat - The pit (Official lyric video) [Video]. https://www.youtube.com/watch?v=2lhFFXNBh5c
Nottingham, J. (2025, November 23) The learning pit [Video]. YouTube. https://www.youtube.com/watch?v=3IMUAOhuO78
When I was a little girl, we lived down the street from a Baptist church. Mom and I would walk there each Sunday, trying to avoid the cracks in the sidewalk so I wouldn't break her back. It was the same place where mom found me on the preacher's lap (with the little red wagon she helped me pack abandoned in front of his desk) the day I decided to run away from home. The same place where mom showed up early to church unaware of the time change and thought the rapture had occured. (A quick run home (sobbing all the while) and a call to Aunt Lucile resolved her fears that we'd been left behind.) The same place where I could hear-feel the organ under the floorboards and into my toes and up into my chest and out my mouth in praise. Where I sang my first solo, Away in a Manger. It's the same place where I squirmed and made noises, played with mom's golden filigree owl necklace until mom pinched me under the arm because the old lady next to her said it would make me still. The same people who heard me screach, "Ouch, you pinched me!" and laughed also watched my baptism. I remember peeking over the water and glass to wave at mom where she sat in our pew. And at 5, I began a life seeking love and service to make the world better.
Church was where I learned about Jesus and love. Where I memorized Bible verses in Vacation Bible School. It's where we read about the end times that mom thought we'd entered way back in the '69 because our clocks didn't automatically change. It's when I didn't know a thing about abortion, gender issues, divorce, disease, war, poverty, or politics of any kind. I just knew my momma loved me and made the world a better place.
Church is also where I learned about persecution of the Christians. That little girl who sat in those pews just couldn't understand why or how folks would want to be mean to people who were to be known by their love.
But I get it now. Here's a test:
They will know you are Christians by:
a. your vote
b. your political party and candidate
c. your financial contributions
d. your stance on governmental and societal issues
e. none of the above
Are we ripe for persecution?
Religion. The church. Government. The Republican Party. The Democratic Party. Christianity. None of these common and proper nouns are recognizable to my child mind or my adult one. And I can't diagram any sense into it. None of these concepts are what I thought they were supposed to mean...or how I thought I was supposed to behave and act. I recognize nothing.
But here we are. Persecution? Why would anyone want to talk ugly or repress folks whose main objective is to love others? Because we are no longer seen as loving. Something I couldn't imagine - persecution of the saints - seems a probable prediction. Voters for Trump have somehow become synonymous for Christian beliefs. Ripe for criticism and attack. And the media - something else I couldn't ever understood is how we'd get to a place where even a child can't tell right from wrong? We are there. I can't make heads nor tails of truth from any of the sources. It's bad fruit not worthy of eating. But shall I starve?
I have friends on both sides of the political and religious spectrums. Friends with folks who don't believe in the magic fairy book or even god of any kind. Family to those alienated by and harmed by the church. All of it...devastating. But I still love them and seek to do good.
At one point in my learning, a teacher explained that Christians were Jesus with skin on. Flesh not spirit. Not a Hannibal Lecter kind of grossness...but a demonstration of love that would show people what God was really like. That's the kind of Christian I want to be...not what I'm seeing described and rightfully mourned out there in reaction to the perceeption of what "Christians" have turned into. I want nothing of that. I hope that my friends can see a better picture of the world through how I'm choosing to live. And love. I hope I can love you like my momma loves me. It's the best kind of Christ-likeness I've ever encountered.
She: Do you have ideas or a resource for revising? I've been recommending Grammar Keepers for editing but I'm not not sure how to help with revision. This is in elementary. And they have Patterns of Power.
Me: The sentence sections in Keepers are also effective for revision. But: the best source of revision is their own papers and ratiocination. There isn't anything out there you can buy. I mean - you can find practice stuff...but there's nothing really out there that tells you how to teach it.
So we talked back and forth for a while. We landed on a purpose, prompts, and source texts. And I found a lot of problems. And I swear, if someone tells me the answers are about diagramming sentences and knowing parts of speech, I'm gonna puke. Try diagramming some of the messes or naming the function and parts of speech that are posed as answer choices. Those old ways ain't gonna work or be a productive use of time. We have to go waaaay beyond naming grammar crap and 1)into how the grammar crap is used to convey meaning 2)and to name what causes the meaning to be obscure because of sentence construction 3)and the function of how words/parts of speech are used in the semantics, syntax, and overarching author's purpose and craft.
The Texts:
Students are reading articles from HMH: Coral Reefs by Erin Spencer, Mariana Trench by Michael and Mary Woods, and 7 Natural Wonders by Raymond Coutu.
The Prompts:
I used a Chart of STAAR Prompts Grades 3-10 by Rene Jackson on Trail of Breadcrumbs to help craft prompts. It was important to generate prompts that used the right genres, correspondence, purposes, and the source texts meaningfully. Originally, students were going to write to experts of the texts to ask questions...but that wouldn't really have been a match to the TEKS. Great idea...worthy of doing. But not really preparation for what they will have to do on STAAR.
I also used CHAT GPT to make some prompts. It was important to write two kinds of prompts - one from the comprehension strand and one for author's purpose.
Comprehension: Write a letter to a friend explaining the importance of coral reefs. Describe what coral reefs are, their role in marine ecosystems, and the various species that live there. Share any interesting facts you learned from "Coral Reefs" by Erin Spencer, and explain why protecting coral reefs is crucial for the environment. (Chat GPT)
Author's Purpose:Examine the key characteristics of how the writers organized the information in x text. In a letter to your teacher, explain how the writers used these characteristics to effectively communicate their main points and make the text interesting to children. (me)
The Problems during the Process:
The process: I began by collecting samples from the STAAR 2024 release. I wrote down the sentences and analyzed what was wrong with them. I'm writing out what the problems are in case others aren't as big of a grammar geek as me. Then I'm going back to add in the solutions.
So...as I am writing these lessons...I'm on answer choice b right now for the first item in the release test...I realize that NONE of this stuff is in our TEKS. None of it. And it's going to take a lot of time. But the work is really about comprehension...deep sentence comprehension and the impact we have on the reader if we are to communicate meaning. And it's about why we struggle with texts when they aren't written well.
I'm realizing that we don't often know why a sentence is all these good things - clear, correct, coherent, effective. Really, those things are about NOT having the things that are unclear, incorrect, incoherent, ineffective...and there's so many ways to be wrong. But are we naming those things for kids? I think we are in editing because that's easy - capitalization, spelling, usage, punctuation...But are we naming those things for kids in revision? It gets messy because what we are presented with in the samples have MANY problems.
I'm going to go ahead and send this part because I want you to have a beginning. I still have 8 more lessons to create from the samples I derived from the released exam. Geeze. It's overwhelming. I feel like this kind of work needs some serious modeling. I've tried to write it out to plan...but what would happen in class after the modeling is up for grabs because you have to take what kids are telling you?
I can't create responses in a meaningful way because I don't know what they have written or what they would say or how they would struggle. I don't know what they would suggest or notice that I have not found by myself. And they always notice stuff and add to the conversation in ways I can't predict. That's why this work is so messy. That's why there is no script or curriculum. There isn't anything out there that can replace the negotiated construction of meaning with learners in the writing process itself. But...how do we teach people to do this kind of work? And what I've created here might miss some important considerations...or be too complicated...
What I Sent Her
Below - I describe three lessons derived from two answer choices from one question on the STAAR test. These lessons represent MULTIPLE concepts for instruction in the revising process and are very complex for 4th grade. Heck. The sentence revisions are complex for me.
Lesson One: When sentences get it right
2023 4th Grade Release Samples from the Revising Section
Target Sentence: Night after night, he just kept coming back.
This sentence is correct, coherent, clear, and effective. Why? What do you notice? Use processes created by Jeff Anderson.
Lesson Two: Problems with order, pronouns, be verbs, and repetition
It was night after night, and he just kept coming back again.
Grammar/Meaning Background and Context
Problem One: Any time you say "It was..." you're beginning a problem with the reader about clarity. What is "it"? We don't know. And, was is a really passive verb - now we know only that something, /it/, /was/exists. This story - the source text - is about a stray cat who shows up and ends up being a pet. Usually, we'd be talking about the pet as the /it/...but that's not what is happening here in the messy answer choice we are given to evaluate.
Problem Two: the focus in the source text is that the cat keeps coming back. The sentence "it was night after night" and the conjunction and dictate that both that sentence/clause and the next one are of equal importance. But that's not true - the importance is on the second clause - that he just kept coming back again. The clause /it was night after night/ is to emphasize how often the cat returned. It's an adverbial in nature and not needed to be a complete sentence that would cause confusion. The important parts of the phrase are /night after night/ while the /it was/ segments add nothing of value and are best deleted for clarity.
Solution: After kids and teachers have a sample essay, it's time for revision. This happens before anything is edited, by the way. We are only working with changes to meaning.
Step One: Take a highlighter and mark any places where you see that you have used a pronoun and a be verb.
Step Two: The teacher shows her writing and makes this statement: "When the reader comes to sentences with "it was," they may have difficulty understanding what /it/ is talking about because the word could mean anything that has been talked about earlier in the text. The reader can have just about anything in their mind - and they could be wrong. When paired with /was/ or other be verbs, the reader only knows and understands that the pronoun and the be verb mean that something (pronoun) exists (be verb). The writer must be careful that their words express their purpose and meaning. It's ok to use /it was/ if the writer means that something exists. But if the writer means something (subject/actor) specific acts in a certain way...then a common or proper noun must be used instead of a pronoun and an action verb is needed instead of a be verb."
Step Three: The teacher models in their own writing. "Let me show you how."
Here's my paper:
Some may think that places like The Great Pyramids or the Taj Mahal are impressive wonders of the world, but the natural wonders are even more impressive. They are made by "forces of nature, such as blowing wind, shifting glaciers, and flowing water" (p.2).
I can do several things to repair possible confusion.
1) I can make a new subject using the quote: "Forces of nature, such as blowing wind, shifting glaciers, and flowing water" (p.2) create naturally occuring wonders that man had no part in creating.
2) I can use specific verbs to replace the be verbs. Notice that I also used a new verb instead of /are/. I used /create/. I had to use the thesaurus to find a new word phrase for /natural/ that fit with what I am trying to explain in the introduction.
3) I can use proper or common nouns to replace the pronoun: Natural wonders are made by "forces of nature, such as blowing wind, shifting glaciers, and flowing water" (p.2).
The teacher makes an anchor chart of solutions for reducing reader confusion:
*Use common and proper nouns to replace pronouns in the subject position in sentences.
*Use action verbs when possible
*Reverse the sentence order to get the main points up front for the reader.
Ask the kids which sentence seems the most vivid and effective in helping the reader understand the meaning. Which one do they like the best? The teacher will then explain which one of the revisions they will keep and use for the paper.
Step Four: Interactive writing with the whole group: Who has a sentence that they would like us to help revise for clarity? Select a student's paper and project. With the class, read the sentence before, the sentence, and the sentence after to get the gist. Use the anchor chart of solutions to help create several revision options. As a class, select the most effective revision. If there is a new solution, name the solution and add it to the anchor chart.
Step Five: Small group collaboration: In small groups of two or three, students craft revision options and select the most clear and effective option. They are using their own papers.
Step Six: Small Group Debrief: Students visit other small groups to see the original and final revised sentences.
Step Seven: Large Group Debrief: What did you learn in your groups about writing with clarity? What was the most common revision technique? Did you see anything new that we need to add to our chart?
Lesson Three: Awkward order, subject placement, concepts, pronouns, be verbs, and general sentence messes
Sample Sentence from answer choices on 2023 4th grade release: Night after night, coming back is what he just kept doing.
This one is a mess.
Grammar/Meaning Background and Context
Problem One: Inaccurate subjects. Coming back serves as the subject of the sentence which makes it confusing. Are we talking about /coming back/ as a concept? No. The cat is coming back.
Problem Two: Awkward construction with word order. We have a verbal as a subject/concept followed by a passive be verb and then added to a clause that is supposed to give another name (predicate nominative) to the subject /coming back/. What's awkward is that /what he just kept doing/ is also vague because /what/ is the connector. I mean...what does /what/ mean in that instance? Not much. Problem Three: Awkward Order and repetition: In prose, we use subjects and then verbs. He just kept coming back. In poetry, we might say, coming back...he just kept coming back. The repetition serves a purpose and adds tension. But just kept doing is...well, weird. Doing what?
Solution: Enter your writing. Check to make sure you are using conventions of prose writing for verb order. A lot of this is fixed by looking for be verbs and how they are presented. We'd follow the same steps as above. Sometimes we have to engineer this crap because nobody really writes like that. (But after practicing...I realize that I did. Weird. See the draft below.)
Dear Jason,
Remember when we went to Moab, Utah? I just read about similar landforms in Raymond Coutu's book, 7 Natural Wonders. Some may think that places like The Great Pyramids or the Taj Mahal are impressive wonders of the world, but the natural wonders are even more impressive. "Forces of nature, such as blowing wind, shifting glaciers, and flowing water" (p.2) create naturally occurring wonders that man had no part in creating. Some of what I read in the book made me rethink what we saw on our trip.
Modeling: The big idea here is that I'm rethinking our trip. But I have other stuff before the big idea. I can reverse the sentence order, or I can make a phrase to introduce the topic. I can even use a complex sentence to show the relationship between the ideas. Add these options to the anchor chart.
Option One: Coutu's book made me rethink what we saw on our trip. or I'm rethinking our trip after reading Coutu's book.
Option Two: After reading Coutu's book, I'm rethinking what we saw on our trip.
Option Three: Because I read about The Grand Canyon in Coutu's book, I'm rethinking what we saw on our trip.
Invitation to notice order: Look over your sentences and the order of your writing. Is your main point the main clause? Can you reverse the order of the clauses? Can you use an introductory phrase? Can you create a complex sentence to show the reader how your ideas are connected?
Invite students to interactive writing...small group collaboration and debrief...then whole class debrief.
The Ending
Basically - I was overwhelmed and too angry to keep writing. And my fingers are cold because I need to get up and turn on the heater in the sunroom. The squirrels are jumping on the roof and continue to bury their nuts alongside the bluejays just outside the window as if I'm not here gutting it out over grammar and how to help our kids and teachers. Journey, ZZ Top Screamers, and old 80's songs are playing on the Alexa behind the empty crock pot. And the water fountain for Youglie is gurgling in the background peacefully. (Youglie refused to get up this morning and demanded the heating blanket to be cranked up to high. What's he going to do when it snows?)
Y'all. The kind of thinking I've described in the three lessons above takes a lot of time. And it takes a lot of analysis and understanding. And, it takes a fundamental pedagogical shift away from a lot of the scripted crap teachers are supposed to love because they won't have to plan lessons - or that they are provided because people think the field is too stupid and unprepared to really teach. Grrrrr.
I wanna come try out these lessons. I wanna see what kids do. But I'd really love to see what a teacher could do with what I've written...I want to see the kind of impact you'd have on your kids and their writing and engagement in school with this type of approach. I dare you. Then we will celebrate positive impact together.
This is a GREAT assignment. Don't get the wrong picture. What we have to consider is the POINT of using the activity. And we have to consider the little people, the audience.
/ed/ does say three sounds. And there is a reason. There are rules. All kinds of them. And all kinds of oddballs that don't follow rules. (Should I dress as an oddball for Halloween? Oh - I'd look like myself. Nevermind.)
Teaching and Leaving Breadcrumbs:
Gretchen Bernabei knows the importance of leaving breadcrumbs. So did Hansel and Gretel. But like Hansel and Gretel - we have to use something more permanent than bread. The cues have to remain so learners can use the ideas when we aren't there anymore.
Here's a story to explain. I had a hard time with Algebra. Dutifully, I took notes. Wrote down all the teacher had chalked onto the dark green board at the front of the room. I could do a problem or two of the even numbers while I was in class. But when I got home, my notes were no help. I could no longer remember, hear, or see what had happened between the lines in the notes. And I didn't really understand what was happening on the lines in the notes.
The instruction on the process was gone. And I was lost. There were no breadcrumbs for me to follow. And I couldn't look up the answers because only the odd ones had the answers in the back of the book. And I still wouldn't know how to get there.
Many times, we are teaching the WHAT. But we leave out the why and the how.
Teaching the Why and How: Point One about Phonics Rules
A group of English I one experts helped draft an example of how they will help students with inferences, text evidence, and writing.
The heart is our brainstorming for WHY we are teaching the lesson and WHY students should care.
The details/means/matters chart is the WHAT, the answers for ELAR.
The arrows below are the brainstorming for future questions and bullet items that will go on the anchor charts and modeling books.
The reason that we knew to do this is that all of us were working with targeted students - observing them during the activity. We asked four questions:
What are you doing?
Why?
Where are you stuck or struggling?
How are you fixing that?
H, the kid I was working with was having no trouble in reading the text or understanding it. But he was struggling about how to tell where his ideas went - "Does this go in the means or matters box?"
In the video at the end, I'll ineloquently. and in terrible handwriting, model the same kind of thing for the phonics lesson on /ed/ sounds. I'll post the video later...still rendering.
Back to /ed/ Phonics Example
So, when teaching phonics lessons, the student I was working with struggled with how we discern the patterns in the words. They could divide the words into the right columns by sound - but they didn't know WHY the words HAD those sounds.
So let's stop and think here for a moment...The student was successful with the phonics activity sort because they already knew how to say the words. Isn't the point of phonics to be able to decode the words? Erm...yes.
The point of this activity is to help with critical thinking and analysis - to infer the pattern or rules that govern the sounds. It's not really phonics anymore.
And...I was wrong about my hypothesis in the video. In looking at the sounds and letter patterns, I tried consonant and vowel patterns, short vs long patterns, and consonant pair patterns. Turns out that the rule is even more/less nuanced. The /ed/ says /t/ when the word is a verb that ends in consonant that has an unvoiced sound. See here for a more detailed explanation.
Playing Out the Rule in Context: Point Two
So let's imagine a kid is reading some words they don't know. Let's say it is even a list and not really reading a real book.
twisted
wished
asked
banged
pressed
Here's what they'd have to think:
1. Take off the ed.
2. Is the word a verb? Yes
3. Is the last sound of the verb an unvoiced sound? Yes - Say /t/ for the /ed/ sound
4. Is the last sound of the verb voiced? Yes - Say /d/ for the /ed/ sound
5. Is the last sound of the verb a d or a t? Yes - Say /ed/ or /id/ for the /ed/ sound. (Depending on your dialect, you say /id/ or /ed/. As if that's not already confusing enough.)
And really. Is that sequence of thinking and questioning what we want kids to do when they are reading words or anything else? Did you even know or realize the three sounds and the rules that govern them? Did your teacher ever tell you that? Did you remember the rules if you did learn it at some point?
No. If you did - you are a linguist. A scientist for language.
2nd Graders aren't Linguists
And shouldn't be. And we, teachers and literacy leaders, shouldn't be using or promoting linguistic pedagogy in the name of "Science of Reading."
Is there value in understanding patterns? Yes. But it's not singularly about reading words and comprehending.
Is there value in understanding and knowing rules. Yes. On the playground for most of them.
But when we are reading words like "wish," we are reading them in sentences and stories to make and use ideas. If the word is "wished," a kid is going to know that the text is probably a fairy tale from the context and genre characteristics. If they say /wishid/, then they are having a vocabulary problem not a phonics problem. And who cares if they say /wisht/ or /wishd/? The way the sounds come out in the mouth, the right thing will probably happen because of physiology or dialect. NOT because the kid knows the word ends in an unvoiced pattern.
Y'all. We need to really examine the purpose of our lessons: HOW we teach them and the impact of our actions.
Making /ed/ words about rules is about word calling. That's not READING. And it damages how kids think about what it means to read.
We should NOT be teaching linguistic science to little kids. We should be teaching them how to make meaning from and with the symbols as they appear in context and use.